一个写的很好的中文 比特币 (可能不适用于以太坊)笔记网址,包含了100篇区块链偏向技术和底层知识的博客:http://www.btccfo.com/category/note/
区块结构
包括 区块头 和 区块体
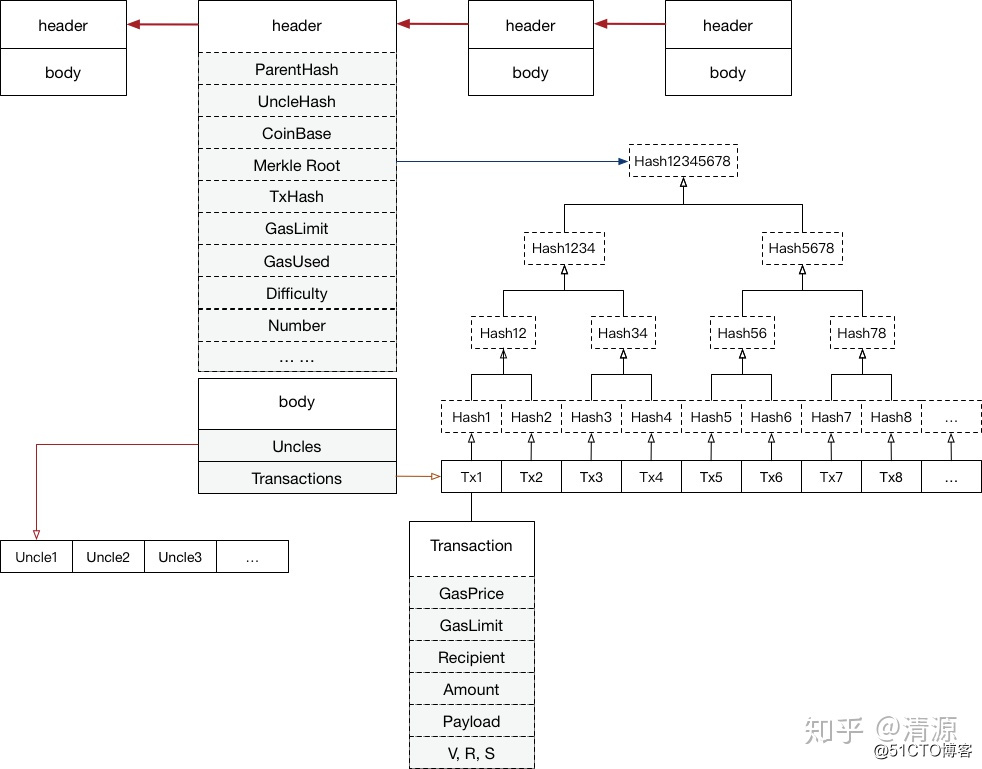
区块头
主要包含了一系列的数值、引用的数值以及哈希值。特别注意有三棵树(状态树、交易树、收据树)的根哈希都存放在区块头中。
区块体
包含 叔块 和 交易列表。这里的交易列表是指一系列交易本身(即包含了to,from,data等信息)
具体查看网址:https://blog.csdn.net/ice_fire_x/article/details/104211388
和https://github.com/laalaguer/ethereum-compass/issues/13
Merkle Patricia tree(MTP)
Merkle Patricia tree是融合了Merkle树和Patricia树(路径压缩前缀树)的结构而形成的。
Merkle树
具体查看网址:https://blog.csdn.net/weixin_37504041/article/details/80474636
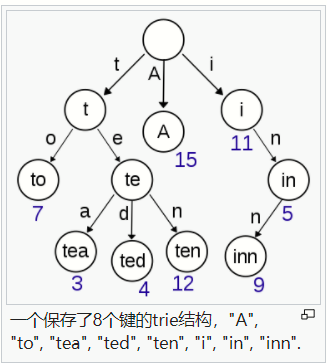
Patricia树
Patricia树的理解:Trie->基数树(Patricia树)
-
称为前缀树或者字典树。用于保存关联数组,其中的键通常是字符串。
-
是一种更节省空间的Trie(前缀树),其中作为唯一子节点的每个节点都与其父节点合并,边既可以表示为元素序列又可以表示为单个元素
MTP
******待完成
具体查看网址:https://blog.csdn.net/itleaks/article/details/79992072
RLP编码和解码
简单来说,RLP就是一种序列化和反序列化的编码模式。
具体查看网址:https://blog.csdn.net/ggq89/article/details/78629008
挖矿
生成Merkle根哈希
矿工创建区块的第一笔交易,称为Coinbase,这笔交易与其他所有即将打包的交易一起通过Merkle树算法生成Merkle根哈希
打包:在挖矿之前,对于当前这个矿工来说,新区块会包含哪些交易就已经确定好了的。这些被确定被包含的交易就是矿工打包的交易。
组装区块头
组装区块头就很简单了,矿工会把上一步计算得到的Merkle根哈希,与随机数Nonce、上个区块hash、难度值、时间戳以及版本号组装成一个区块头。这里的随机数是矿工唯一能改变的数值,矿工会不停的改变随机数,计算区块头的hash,直到得到的hash值匹配上全网目标值为止。
计算目标值
即计算出符合区块链目标的值,比如满足前十个都是0的值
具体查看网址:https://blog.csdn.net/weixin_37504041/article/details/103792215
或https://www.tangshuang.net/4097.html
节点类型
全节点
- 存储完整的区块链数据。
- 参与区块验证,验证所有区块和状态。
- 所有状态都可以从一个全节点推出。
- 为网络提供服务,并按照请求提供数据。
轻节点
- 存储头链并请求其他所有内容。
- 可以对照区块头中的状态根来验证数据的有效性。
- 对于低容量的设备,如嵌入式设备或移动电话来说是有用的,这些设备无法储存数千兆字节的区块链数据。
归档节点
- 存储保留在全节点中的所有内容,并建立一个历史状态的归档。 如果您想查询区块 #4,000,000 的帐户余额等内容,或者简单可靠地使用 OpenEthereum 在不挖坑的情况下测试自己的交易集,就需要这样做。
- 这些数据的数据量会达到TB级别,这使得存档节点对普通用户的吸引力降低,但对于诸如区块浏览器、钱包供应商和链分析之类的服务而言却很方便。
以存档以外的任何方式同步客户端将导致修剪的区块链数据。 这意味着,没有所有历史状态的档案,但是整个节点都可以按需构建它们。
具体查看网址:https://ethereum.org/zh/developers/docs/nodes-and-clients/#node-types
同步策略
完全同步
完整下载所有区块(包括区块头、交易和接收的数据),并通过执行 每个区块的每个交易 来逐步生成区块链的状态。
- 通过验证每笔交易,最大限度地减少信任并实现最高安全性。
- 随着交易数量的增加,处理所有交易可能需要几天到几周时间。
快速同步
快速同步会下载所有区块(包括区块头、交易和接收的数据),验证所有区块头,下载区块状态并对区块头进行验证。
- 依赖共识机制的安全性。
- 同步只需要几个小时。
轻量同步
轻量客户端下载所有区块头、区块数据并对其进行随机验证。 仅从信任的检查点同步区块链信息。
- 仅获取最新状态,同时依赖于对开发者的信任和共识机制。
- 客户端已准备好在几分钟内使用当前网络状态
具体查看网址:https://ethereum.org/zh/developers/docs/nodes-and-clients/#sync-modes
全节点如何同步(仅指达到最高高度)区块链
- 连接到对等节点,发送version消息,这是因为该消息中含有的BestHeight字段标示了一个节点当前的区块链高度(区块数量)。节点可以从它的对等节点中得到版本消息,了解双方各自有多少区块,从而可以与其自身区块链所拥有的区块数量进行比较。
- 对等节点们会交换一个getblocks消息,其中包含他们本地区块链的顶端区块哈希值(指纹)
- 更高的节点通过使用inv(inventory)消息把这些区块的哈希值传播出去。缺少这些区块的节点便可以通过各自发送的getdata消息来请求得到全区块信息,这些节点会向所有与之相连的对等节点请求区块,并通过分摊工作量的方式进行下载
- 如果一个节点需要更新大量区块,它会在上一请求完成后才发送对新区块的请求,从而允许对等节点控制更新速度,不至于压垮网络
具体查看网址:http://www.btccfo.com/blockchain-tec/769
read list & 问题:
https://zhuanlan.zhihu.com/p/31022434
https://blog.csdn.net/ice_fire_x/article/details/104211388
https://blog.51cto.com/u_9634496/3077006
https://learnblockchain.cn/2020/01/27/7c1fcd777d7b
- 交易树存放在levelDB中吗?每一个区块有一个交易树,这种特殊之处在存放的时候有体现吗?交易树的值是什么,因为交易已经在区块中存过了,那交易树的值是什么
- 收据树存在哪的?收据树存的值是什么
以太坊
参数编码
特别需要注意的是以下这些类型,他们都不仅仅只存本身的data,还要存offset、length,并且存储规则不同。在这些结构相互结合时(比如结构体数组)更复杂。
- 变长普通类型数组(比如uint256[] , bytes32[] , string等)
- 结构体
- 变长结构体数组
- 变长二维数组
具体查看网址:https://ctf-wiki.org/blockchain/ethereum/selector-encoding/
数据结构存储
如果仅仅是定义了结构体X,而没有实例化X,是不占ID的。
比如
1
2
3
4
5
6
7
8
9
10contract data{
uint a;//存储在插槽0中
struct b {
uint x;
uint y;
}//no slot
uint c;//存储在插槽1中
}变长数组、mapping
1
2
3
4
5
6
7contract data{
uint[] a;
//插槽0中存储该数组长度。从插槽keccak256(0)开始依次存uint数据
mapping(address=>uint) b;
//插槽1中什么也不存。对于b[0x123..]而言,在插槽keccak256(abi.encodePacked(0x123...,1))中存储了uint数据
}abi.encodePacked(data,data,…)的意义是将数据进行拼接。从二进制的角度讲,如果对010101和000000进行拼接,那么最终得到的是010101000000
疑问:mapping在计算hash的时候,究竟是紧打包吗,即abi.encodePacked
可以参考网址:https://ctf-wiki.org/blockchain/ethereum/storage/
WEB3
使用web.py:直接pip install web3
WEB3.py:https://web3py.readthedocs.io/en/latest/index.html
免费的远程节点提供程序:https://infura.io/
from web3.auto.infura import w3
w3.eth.getCode(“0x……”)
非常好用,慢慢探索